Becca's ITP Sketchbook

A couple of us after our LOC visit went to the Artechhouse Cherry Blossom show. It had 5 different pieces to interact with – more soon ❤ ( img from blog ihitthebutton)

This past week we went as a class with Jer to visit the Library of Congress! We got to meet the people skyping with our class this semester and saw many things from different collections/departments. Everyone was very generous with their time and at the end we all got our LOC readers card for future research ❤
I was able to stop by the Young Readers Center for a a little bit before 4pm. Their program coordinator Sasha has been really helpful and told me that they hope to highlight Strong Women in their book collection coming up soon for the in memory of the Women’s suffrage movement.
Departments we visited:
And during the last hour stopped by the Young reader’s center and the Maps collection. It was really cool seeing the maps that Rashida and Effy requested of India and Guangzhou. I was able to look at maps of Ireland from the 1500s and Karina started looking at different representations of wind in the map marginalia. More soon!


Brainstorming different possible playful search engine methods for exploring different curated collections in the Library of Congress Young Readers Center. How can we allow for both curation but still a sense of serendipity? Thinking of applying the idea of a paper fortune teller simulation, where maybe its an interactive p5js sketch that navigates you using a similar layout as above. Or maybe its a program that generates one for you to fold yourself for older visitors.


For the test I search a range of children’s books based around different seasons of the year to do a quick paper prototype of the search mechanism. Although the paper fortune teller restricts the title amounts to 8 due to its 8 reveal tabs, maybe from a p5js could access / sift through a larger amount of titles.
A couple questions are leading me to wonder that maybe fuzzy dice or something that can be rolled like dice, with FSR sensors on each face would be a more logical mechanism if looking for future modularity/ interchangeability?
For the Fortune teller concept to work currently its very dependent on the visual illustration of the concepts. And would be unsure how it could become something that librarians could easily change out unless they’re excited to create their own illustrations for their future curated lists? Right now its a very rigid design in that way. How to make it more fluid / interchangeable?








First class starts off with a Skype visit with LOC web archiving team: https://www.loc.gov/programs/web-archiving/about-this-program/

“I invite to dig deeper into these project and make contact with the people involved.” – Bergis Jules

Not All Information Wants to Be Free – Tara Robertson: http://eprints.rclis.org/32463/1/Applying%20Library%20Values%20to%20Emerging%20Technology_Chapter%2015.pdf
“Best Practices for Ethical Digitization – There are four things that people who are digitizing culturally sensitive materials can do to try and make their projects more ethical and appropriate. First, a standard librarian technique is to do an environmental scan and learn from what other people have done. Several digitization projects that have handled culturally sensitive materials have put out reports detailing some of their ethical concerns and processes. Second, it is important to have clear contact information posted so that people know whom they can talk to if they have concerns or more information. Third, use technology built by projects that are thinking thoughtfully and deeply about values and ethics. Fourth, librarians need to develop skills in working with communities to determine what should be digitized and what kind of access is appropriate.”
It can be confusing and intimidating to figure out who to contact at a university, museum, or cultural institution. It is important to make it easy to find out who to contact if one has concerns or additional information about digital collections. It’s also useful to state that your institution is open to receiving more information about specific content and open to requests for content to be removed. It is also important to have clear policies that are posted publically so that people know about criteria, timelines, and processes for inquiries and complaints.
The New Zealand Electronic Text Collection describes how they will keep the communication lines open with communities:
We will provide avenues by which people can place general feedback (via links to the message boards) or contact us directly. If whānau want to discuss with us suppressing images of their tupuna then we are prepared to do so (with the inclusion of a statement as a placeholder within the text stating why the image is no longer displayed). Alternatively, if they had information that they would like placed with their tupuna’s name, then we are open to adding it.”
3. Use Appropriate Technology
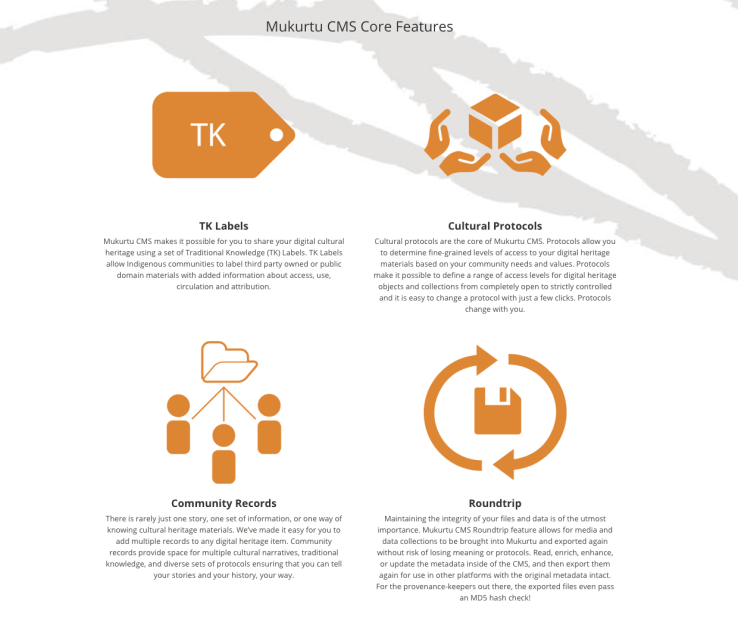
The Murkutu project has been leading the way in building an open source platform to allow appropriate access to culturally sensitive materials, specifically indigenous stories, knowledge, and cultural materials. The Murkutu platform is built and configurable to reflect how specific communities access and share knowledge. Both items and people have permissions associated with them, which can facilitate granular and appropriate access. The software also supports traditional knowledge labels, which were developed “to support Native, First Nations, Aboriginal, and Indigenous communities in the management of their intellectual property and cultural heritage specifically within the digital environment.”25

DocNow is a software project that started after the Ferguson riots. They are building appropriate software tools for the ethical collection of social media content. They are building into their free open-source tools the key concept of consent. DocNow project also seeks to build a critical community of practice: While we’re not yet sure what this community will end up looking like or how formal or informal it will be, we want to build on this momentum and continue to encourage conversations around what it means to build archives of social media data for the long term, not replicating oppressive models of digital data collection and dissemination, and respecting content owners privacy and humanity, while at the same time upholding our responsibility to be vigilant in countering the erasure of people of color from the historical record.26 I admire how they are explicit and clear in identifying their values—like Black Lives Matter—and how those values influence the software tools that they are developing. Ed Summers states that “I think what we are hoping to do is build a tool that doesn’t just do things because it’s possible, but has some values built into it.”
4. Work with communities to determine what is appropriate
Libraries and other cultural institutions need to build relationships and work with communities more, and community consultation should include discussions Not All Information Wants to be Free 237 about appropriate use of the content. In both the case of OOB and Spare Rib, the digitizing agency pushed a more permissive license than some contributors were comfortable with. Perhaps if the consultation process included a conversation on copyright and the different types of Creative Commons’ licenses, there might have been more willingness to consider a CC-BY license and informed consent to pick the best license for individuals and the community, not the institution and funding agencies. Academic libraries can learn from public libraries’ community development initiatives.
As librarians, it’s uncomfortable but necessary for us to give up some of our power and work with community members on equal ground. Having an advisory board that includes community members should be a minimum requirement for digitization projects. Both the Spare Rib and DocNow have robust Advisory Boards.



From syllabus:
The Library of Congress is a definitively colonial institution. Throughout its history, voices of indigenous people have been in turn ignored, erased, and neglected. In this class we’ll examine this problematic history and look at some ways that indigeneity is being re-addressed. In particular, we’ll investigate the story of how 31 cylinders containing Passamaquoddy songs have revently been restored and re-born.
Guest Speaker: Jane Anderson
Readings, etc:
Anxieties of Authorship in Colonial Archives – Jane Anderson et al : https://static1.squarespace.com/static/55cfbe2de4b02774e51fac68/t/55d0ed0fe4b02b29043a1cec/1439755535710/Anxieties+of+Authorship.pdf
Understanding Indigenous Data Sovereignty – Tahu Kakatai https://www.youtube.com/watch?v=BWX8qS0mTAg
Ancestral Voices Roundtable – http://www.loc.gov/today/cyberlc/feature_wdesc.php?rec=8530&loclr=eanw
Artist in the Archive Episode 8: https://artistinthearchive.podbean.com/e/episode-8-thirty-one-cylinders/

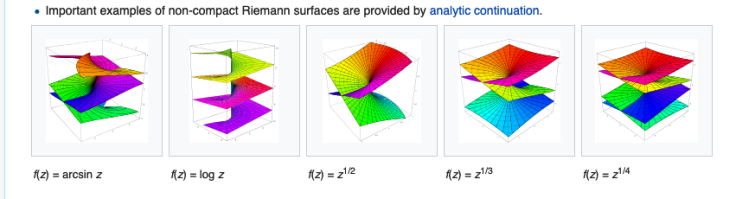
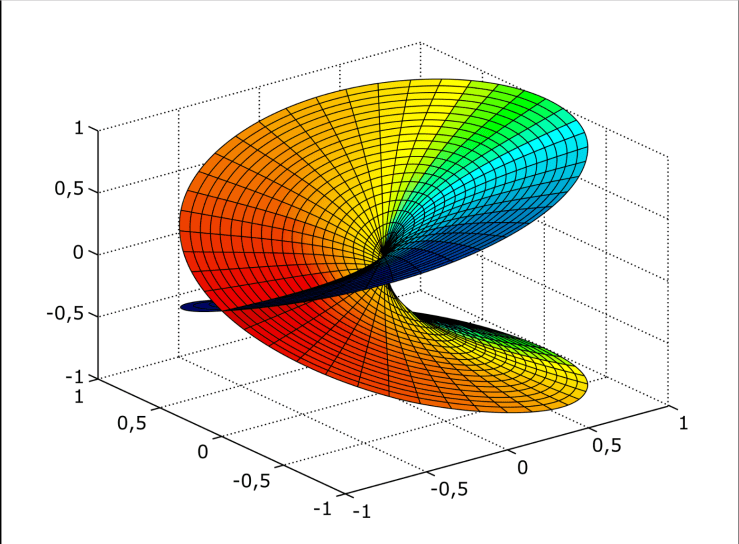
When diving into the LOC archives I came across a collection of archived blogs that celebrated math and science. One that I enjoyed was “grandmama’s in stem” where it went out to prove against the saying “my grandma could do that” implying a lack of knowledge and know how. To counter the saying the author posted submissions about various women in stem – although I disagree with her being a grandma [was only a mother at the time of her passing, and also passed at a young 40 due to breast cancer] I was inspired to dig deeper and learn more about Riemann Surfaces.
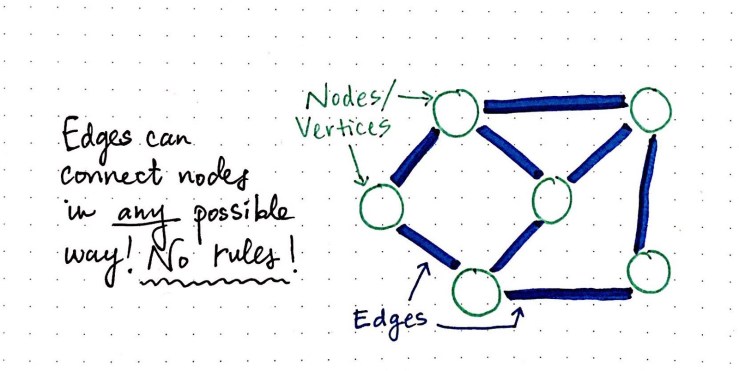
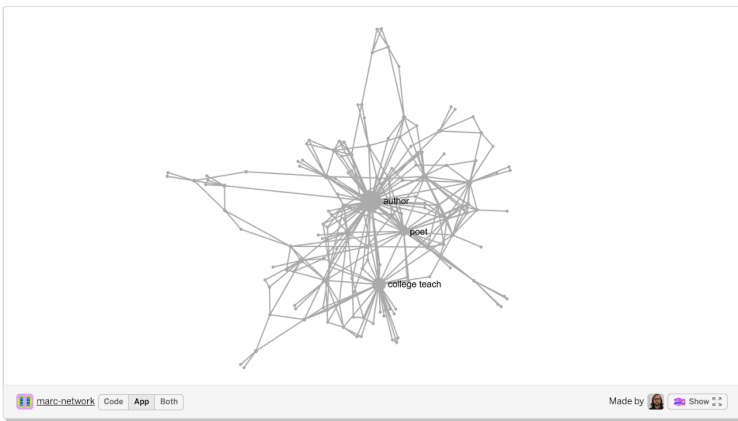
For this week’s homework, we’re building off of the MARC template overviewed in class to create investigative “excavations” of the Library of Congress’ digital archive via the MARC records . How can we reveal something new to us and others through these new connections? We talked about about nodes and edges via graph theory, and apply that sort of thinking to the MARC records using Sigma.js + Node.js.
How do we get from looking at Marc to some interesting computational questions? In class we took a look at 4 sort of methodical approaches to take/ think about when approaching a collection: composition, comparison, distribution, and relation. We also talked about approaching the process in different ways, like from the view of traditional archeological excavations/digs and their fieldnotes. How can we borrow that sort of dissection and physical representation of process & data to our MARC explorations?